
Trendscouts nehmen Machine Learning unter die Lupe: Kundensegmentierung (Teil 2)
Herzlich Willkommen zum zweiten Teil des Artikels „Trendscouts nehmen Machine Learning unter die Lupe: Kundensegmentierung“. Im ersten Teil des Artikels habe ich erklärt, warum wir Trendscouts uns mit Fragen zur Relevanz von Machine Learning für die Finanzindustrie beschäftigen und wie Machine Learning überhaupt funktioniert. Die erste Frage habe ich bereits an dem Anwendungsbeispiel der Kundensegmentierung erläutert. In diesem Artikel werde ich die zweite Frage beantworten und anhand des erläuterten k-Means-Algorithmus zeigen, wie die Kundensegmentierung durch Machine Learning umgesetzt wird.
Was passiert im k-Means-Algorithmus?
Wer an dieser Stelle keine Lust hat weiter zu lesen, kann sich auch von Stanford Professor Andrew Ng diesen Algorithmus in 12 Minuten erklären lassen.
Für alle, die lieber lesen möchten oder gerade kein Video mit ihrem Datenvolumen streamen möchten, werde ich jetzt die vier essentiellen Schritte des k-Means-Algorithmus erklären. Um die Erklärung möglichst kurz zu halten, werde ich an dieser Stelle nicht weiter auf einzelne Schwierigkeiten, wie Datengrundlage oder einzelne Entscheidungskriterien, eingehen. Hinterlassen Sie mir jedoch gerne Fragen in den Kommentaren.
Welche Schwierigkeiten sehen Sie bei diesem Algorithmus?
Vorbereitungen
Bevor wir mit dem eigentlichen k-Means-Algorithmus beginnen, müssen wir zunächst zwei Dinge festlegen:
a) Anhand welcher Merkmale sollen die Kunden segmentiert werden?
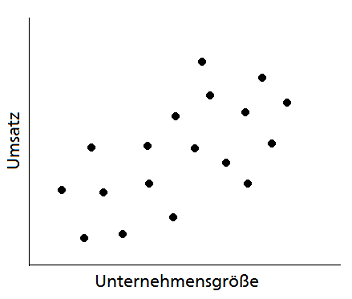
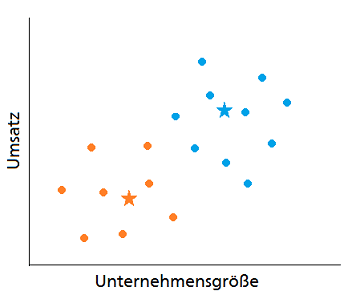
Wir haben bereits festgestellt, dass Kunden viele Merkmale haben. In diesem Beispiel beschränken wir uns aus Darstellungszwecken auf zwei Merkmale: Unternehmensgröße und Umsatz. Wir behalten aber im Hinterkopf, dass der Algorithmus erst seine volle Stärke entfaltet, wenn mehrere Merkmale einbezogen werden. In der nachfolgenden Grafik sind die Kunden anhand der Merkmale Unternehmensgröße und Umsatz dargestellt.
b) In wie viele Segmente sollen die Kunden eingeteilt werden?
Außerdem legen wir fest, in wie viele Segmente die Kunden eingeteilt werden sollen. In diesem Beispiel ist für einen Menschen zu erkennen, dass es sinnvoll ist die Kunden in zwei Segmente zu teilen. In der Praxis ist die Festlegung der Anzahl der Segmente eine schwierige Fragestellung, auf die ich in diesem Artikel nicht weiter eingehen werde.
Nun können wir mit dem eigentlichen Algorithmus beginnen.
1. Segmentzentren festlegen
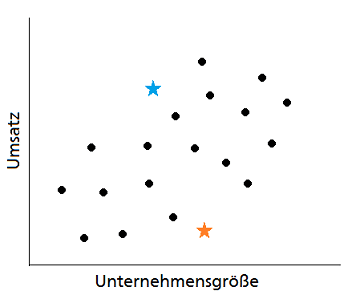
Als erstes werden pro Segment je ein Segmentzentrum (hier Stern) festgelegt. Da wir entschieden haben, die Kunden in zwei Segmente zu unterteilen, werden zwei Segmentzentren (blau für Segment 1 und orange für Segment 2) initialisiert. Diese Punkte repräsentieren die Mittelpunkte der Segmente und werden im allerersten Schritt willkürlich irgendwo auf unserem Graphen platziert.
2. Zuordnung der Kunden zum nächstgelegenen Segmentzentrum
Nach der Initialisierung der Segmentzentren (Sterne) erfolgt die erste Segmentierung. Dafür wird für jeden Kunden untersucht, ob er näher an dem Mittelpunkt von Segment 1 oder Segment 2 liegt und entsprechend dem näheren Segment zugeordnet. Die Zuordnung wird in diesem Bespiel durch die Einfärbung des Punktes in der entsprechenden Farbe des Segmentes repräsentiert.
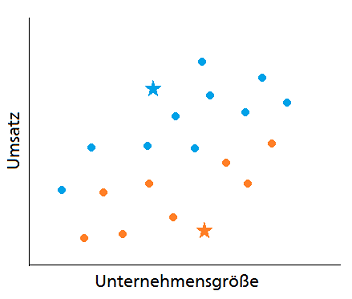
Je nachdem, wo im ersten Schritt die Segmentzentren festgelegt worden sind, kann die Segmentierung – wie in diesem Fall – nach der ersten Iteration deutlich danebenliegen. Es muss also eine Anpassung erfolgen.
3. Segment-Mittelpunkt neu ausrichten
Als nächstes werden die Mittelpunkte der Segmente neu platziert. Dazu wird der Segmentmittelpunkt aus dem Durchschnitt – daher k-Means (engl. für Mittelwert) – aller Punkte dieses Segmentes berechnet.
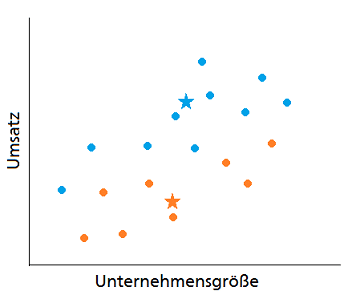
4. Wiederholen von Schritt 2 und 3
Nach der Neuausrichtung der Segmentzentren werden die letzten zwei Schritte wiederholt: Erst wird wieder jeder Kunde dem näheren Segmentzentrum zugeordnet und anschließend das Segmentzentrum neu platziert bis sich das Segmentzentrum nicht mehr verschiebt. Der Algorithmus ist nämlich dann am Ende, wenn sich nach einer Iteration keine Veränderung des Segmentes ergibt. Nach ein paar Wiederholungen sieht man bereits, dass der Algorithmus von alleine die Kunden in sinnvolle Segmente teilt.
Technische Trivia am Rande: Prototyping mit einer Zeile Code
Wer nicht selber programmiert, hat sich sicherlich schon mal gefragt, warum es eigentlich so viele verschiedene Programmiersprachen gibt. Das liegt daran, dass verschiedene Programmiersprachen auch unterschiedliche Stärken und Schwächen besitzen. Zur Veranschaulichung: Während es einige Zeilen Code benötigen würde, um den k-Means-Algorithmus z.B. in der Programmiersprache Java zu implementieren, ist der Code für den k-Means-Algorithmus z.B. in der Programmiersprache Matlab genau eine Zeile lang.
Leider ist es aber schwierig, Webanwendungen in mathematischen Tools wie Matlab zu implementieren. Daher werden Machine Learning-Algorithmen in der Regel mit Programmiersprachen, die ihre Stärken in der Mathematik haben, wie R, Matlab oder dem freien Pendant GNU Octave, prototypisch getestet, bevor sie dann mit z.B. Java oder PHP in Webanwendungen implementiert werden.
Fazit
Machine Learning wird auch für die Finanzindustrie immer relevanter. Daher ist es auch für uns wichtig, grundlegend zu verstehen, wie Machine Learning eigentlich funktioniert. In diesem Artikel habe ich am Anwendungsfall der Kundensegmentierung erklärt, dass eine Maschine dafür im Grunde genommen nur zwei Schritte ausführt – zum einen die Zuordnung zum Segment und zum anderen die Ausrichtung des Segmentzentrums. Obwohl in der Praxis noch viele weitere Aspekte dazu gehören (z.B. woher wissen wir wie viele Segmente es geben soll?), kennen wir nun die Grundzüge des Clustering-Algorithmus k-Means.
Wenn Sie Anwendungsfälle von Machine Learning kennen, deren technische Hintergründe Sie gerne kennenlernen wollen, hinterlassen Sie sie doch gerne in den Kommentaren. Ich freue mich auf ihre Fragen und Anregungen!
Quellen
Business Science: Customer Segmentation Part 1: k-Means Clustering. http://www.business-science.io/business/2016/08/07/CustomerSegmentationPt1.html (03.08.2017)
Gisler, Claudio: Neue Möglichkeiten für die Kundensegmentierung bei Banken. https://www.der-bank-blog.de/neue-moeglichkeiten-kundensegmentierung/marketing/27801/ (30.07.2017).
Grewal, Ami: Auf dem Vormarsch: Machine Learning und Artificial Intelligence. https://blog.gft.com/de/2017/03/03/machine-learning-und-artificial-intelligence/ (30.07.2017).
Ng, Andrew: Clustering – kMeans Algorithm. https://www.youtube.com/watch?v=hDmNF9JG3lo (03.08.2017).
Peters, Anja: Befragung: Kundensegmentierung in Banken und Sparkassen – heute und morgen. https://www.it-finanzmagazin.de/befragung-kundensegmentierung-in-banken-und-sparkassen-heute-und-morgen-25548/ (03.08.2017).
Diese Themen interessieren uns
Learnings from ECB Exploratory Phase – Part 2: Review of the HTLC Mechanism
Learnings from ECB Exploratory Phase – Part 1
Hallo,
sehr spannendes Thema, mit dem ich mich auch beruflich gerne auseinandersetze, da die Zielkundenclusterung für die effektive Kundenansprache, ein wichtiges Thema ist.
Mich würden genauere Informationen zu den o.g. und nicht weiter erklärten „Schwierigkeiten“ und „Datengrundlage“ interessieren.
Danke im Voraus für Ihre Beantwortung.
Viele Grüße
Elke Grauert
Hallo Frau Grauert,
vielen Dank für Ihre Frage.
Allgemein stellt die Qualität der Daten eine Herausforderung für alle Themen im Big Data und Machine Learning dar. Hier müssen Fragen wie z.B. „Wie handhabe ich unvollständige Datensätze?“ gestellt werden. In diesem Fall wäre die Fragen: Wenn ich die Unternehmensgröße zu Kunde A weiß, aber Information über den Umsatz von Kunde A fehlt, bewerte ich den Umsatz mit 0 € oder nehme ich Kunde A aus dem Datensatz raus? Die erste Variante würde zu Verfälschungen des Ergebnisses führen und die zweite Variante würde meinen Datensatz verkleinern und möglicherweise die Qualität des Modells beeinflussen (z.B. wenn ich 10 Kunden habe und 5 davon unvollständige Daten haben).
Außerdem muss ich überhaupt wissen, dass der Datensatz unvollständig ist. In diesem Beispiel könnte die Information „Umsatz“ unbefüllt sein oder aber auch mit „0“ befüllt sein. Woher weiß ich, dass mir die Information zu „Umsatz“ fehlt oder dass der Umsatz tatsächlich 0€ betrug.
Nun zu den Problemen von k-Means:
1. Welche Merkmale benutze ich?
Die Auswahl der Merkmale und deren sinnvolle Darstellung kann schon die erste Hürde sein. Während die erste Frage „Wonach gruppiere ich meine Kunden?“ eine Frage ist, die der Kundenberater wahrscheinlich noch ziemlich gut beantworten kann, ist eine sinnvolle Darstellung der Merkmale schwierig. Hier muss man die Merkmale nach „kontinuierlichen“ und „diskreten“ Typen unterscheiden. Merkmale wie Umsatz, Unternehmensgröße sind kontinuierlich, weil sie eine Zahlenfolge bilden. Was ist aber, wenn ich meine Kunden nach Branchen gruppieren möchte. Branchen sind diskrete Merkmale, da sie nicht in eine sinnige Reihenfolge wie 1 < 2 < 3 … gebracht werden können.
2. Woher weiß ich in wie viele Segmente ich meine Daten teilen soll.
Bei unserem Beispiel war für einen Menschen klar, dass es zwei Segmente geben muss – das haben wir sofort gesehen. Hätten wir jedoch die Segmentanzahl auf 3 festgelegt, wäre das Ergebnis unbrauchbar gewesen. In der Regel, werden Sie Ihren Datnsatz vorher nicht grafisch darstellen und dann festlegen, wie viele Segmente Sie möchten. Dies ist eine aktuelle Fragestellung in der Forschung.
3. Weitere technische Grenzen von k-Means:
– k-Means geht davon aus, dass ein Segment kreisförmig ist mit einem Zentrum. Was ist, wenn für die Cluster eine andere Form sinnvoller wäre?
– k-Means geht davon aus, dass die Segmente den gleichen Radius haben. Was passiert also, wenn ich ein großes Hauptcluster habe und direkt neben dran ein kleineres Cluster?
Ich hoffe, ich konnte hiermit ein paar Schwierigkeiten von k-Means deutlich machen.
Viele Grüße
Leonie Sperner